Log-Structured Merge Trees
TLDR
“If there was an absolutely optimal storage engine for every conceivable use case, everyone would use it. But since no such engine exists, we must choose wisely.”
Database design is fundamentally an exercise in trade-offs. Every storage engine embodies a set of choices shaped by the workload it is meant to serve: read-heavy versus write-heavy, analytical versus transactional, latency-sensitive versus throughput-oriented.
B-trees have long been the dominant storage structure in general-purpose databases—particularly those optimized for OLTP workloads, point lookups, and range scans. Systems such as PostgreSQL, MySQL, MariaDB, Oracle, and SQL Server rely on B-trees because they offer predictable performance characteristics. By maintaining a balanced, high-fanout ordered index, B-trees bound the cost of both reads and writes through synchronous, in-place updates, favoring consistent per-operation latency over peak write throughput. Point lookups require O(logb n) page accesses, while range scans require O(logb n + k), where b is the branching factor and k is the number of entries scanned.
That same ordered structure, however, imposes significant costs on write performance. Maintaining order forces writes to become random I/O rather than sequential I/O, since each update must modify a specific page determined by the index. In a B-tree, updates are performed in place: the target page is read from disk, modified, and written back to its original physical location. As write volume increases, the cumulative cost of these random reads and writes—along with the overhead of preserving index order—begins to dominate, limiting overall write throughput.1.
Log-structured merge (LSM) trees address this bottleneck by transforming random writes into sequential ones. Instead of updating data in place, writes are batched and applied out of place. New versions of data are written sequentially to disk, while older versions are left untouched and reconciled later. In the LSM model, updates are deferred, sequential, and append-only, allowing the system to maximize write throughput.
An LSM tree consists of both an in-memory component and a set of on-disk structures. Incoming writes are first appended sequentially to a write-ahead log (WAL) to ensure durability, then applied to an in-memory data structure called the memtable. The memtable maintains keys in sorted order, enabling fast reads and writes for recently updated data. When the memtable fills, it is flushed to disk as an immutable, sorted file known as a Sorted String Table (SSTable).
Conceptually, an LSM tree can be understood as a multi-level differential index. Recent inserts, updates, and deletes are accumulated in small, fast-to-update structures—first in memory, then in progressively larger on-disk levels. Over time, these changes are merged and consolidated through compaction, allowing the system to sustain high write throughput without repeatedly rewriting existing data.2.
Newest
│
├── Memtable ← differential
├── L0 SSTables ← differential
├── L1 SSTables ← differential (usually)
│
├── L2 / L3 / … / Ln ← base
│
Oldest
Memtable
The memtable is the in-memory representation of the most recent writes applied to an LSM tree, before those writes are flushed to disk as SSTables. Conceptually, it serves as both the primary write target and the freshest source of truth for reads. Because it may contain newer versions of keys than those stored on disk, every read must consult the memtable before accessing on-disk SSTables.
When a memtable reaches its configured size limit, it transitions from mutable to immutable. To avoid write stalls, the storage engine immediately switches to a new writable memtable, while the full one is flushed asynchronously in the background. Once the flush completes, the immutable memtable can be safely discarded. At any given time, only one memtable accepts writes, while one or more immutable memtables may coexist to serve reads. In practice, most LSM engines implement an effective memtable pool to minimize flush-induced latency spikes.
Memtable pool
├─ One active mutable memtable (accepts writes)
├─ Immutable memtable #1 (being flushed)
├─ Other immutable memtables (queued to be flushed)
└─ …
At its core, the memtable is implemented using a data structure that maintains records in total order by key, such as a red-black tree, an AVL tree, or a skip list. Because SSTables are immutable and sorted, the memtable must be able to emit its contents in sorted order during a flush. For example, if implemented as a balanced binary search tree, an in-order traversal yields sorted keys in O(n) time.
Functional requirements of the memtable
Atomic writes
Every individual
putordeleteoperation must be atomic. Concurrent updates to the same key must never leave the memtable in an inconsistent state.Linearizability (read-your-writes)
Writes must be globally ordered and immediately visible once acknowledged. If Thread A writes a value, Thread B must be able to observe that write upon completion, regardless of where the write originated.
Snapshot isolation / consistent reads
During range scans or long-running reads, the memtable must present a consistent snapshot of the data, even as concurrent writes continue.
Bidirectional iteration
Beyond point lookups, the memtable must support efficient forward and reverse range scans. This capability is essential both for user queries and for generating sorted SSTables during flushes, which makes hash-table-based memtable designs unsuitable.
Support for versioning (MVCC)
To correctly handle updates and deletes, the memtable must retain multiple versions of the same key, typically distinguished by sequence numbers or timestamps.
Non-functional requirements of the memtable
High write throughput (low contention)
The memtable should minimize global locks. Modern implementations often rely on lock-free or wait-free data structures to sustain concurrent writes.
Low read latency
Reads should proceed without being blocked by concurrent writes.
Bounded memory usage
The memtable must accurately track its memory footprint so that flushes are triggered before exhausting allocated RAM.
Predictable P99 latency
Switching from one memtable to the next should not introduce latency spikes.
Non-blocking long-lived iterators
Background flushes or large user scans may take seconds to complete. Iterators must not hold coarse-grained locks that would stall new writes.
Skip lists as a memtable data structure
Skip lists have become a popular choice for memtable implementations in modern LSM-based storage engines, including RocksDB, Cassandra, HBase, ScyllaDB, Pebble, and others.
First, skip lists support lock-free concurrency. Rebalancing a tree requires structural rotations that may affect entire root-to-leaf paths, forcing large sections of the tree to be locked. Under write-heavy workloads, this contention severely impacts tail latency. In contrast, skip lists are updated by adjusting pointers at multiple levels and can be implemented using atomic compare-and-swap (CAS) operations.
Second, skip lists are naturally well suited to snapshot isolation. Because nodes are never moved once inserted, a reader can safely traverse the list knowing that pointer order will remain valid even as concurrent writes occur. To support MVCC, keys are typically stored as (key, sequence_number) pairs.
Third, skip lists work well with arena allocation. Instead of allocating each node individually, the engine requests a large contiguous memory block (e.g., 8 MB) and performs simple bump-pointer allocation. Nodes created around the same time are physically adjacent in memory, improving cache locality and making deallocation of flushed memtables an O(1) operation3.
Finally, skip lists provide efficient bidirectional iteration and probabilistic balancing. While strictly balanced trees guarantee a height of logb n, maintaining that guarantee under heavy write pressure is expensive. Skip lists achieve O(log1/p n) average-case performance without ever requiring a global rebalance where p is the level probability (usually p = 0.25 or 0.5). Although a theoretical worst case of O(n) exists, the probability of severe imbalance is negligible in practice.
Write-ahead log (WAL)
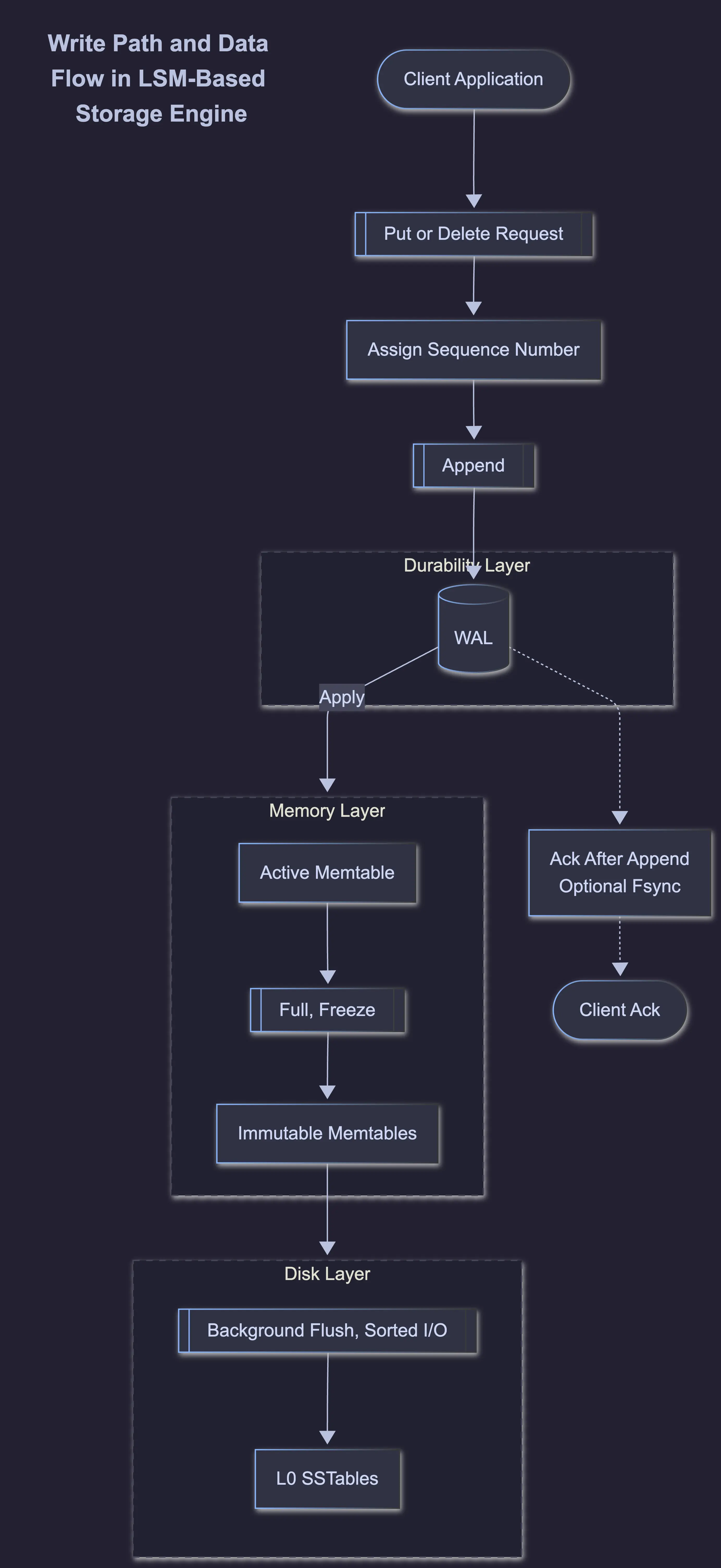
Every write operation proceeds in two logical steps. First, the operation (for example, " SET user:123" = "laura") is appended to the end of the WAL. Second, once the log entry is safely persisted—often after an fsync()—the write is applied to the memtable.
Although these steps are logically ordered, they are not always executed synchronously. In the strictest durability mode, the engine invokes fsync() after every append, forcing data from the OS page cache to disk before acknowledging the write. In higher-throughput configurations, WAL writes may be buffered, allowing the engine to apply updates to the memtable and return success before the data is physically persisted.
Modern engines such as RocksDB and Pebble employ pipelined writes. One thread may be flushing a batch of accumulated updates to the WAL while another simultaneously applies a previously logged batch to the memtable. While the logical ordering—WAL first, memtable second—is preserved, the hardware performs both steps concurrently on different batches.
The WAL exists solely to reconstruct memtable state after a crash. Each WAL record typically includes:
- A CRC-32 checksum for integrity verification
- A record type indicator (e.g., full record or fragment)
- Operation data, including keys, values, and tombstones
Upon restart, the storage engine scans WAL files in chronological order, validates each record, reconstructs the memtable, and resumes operation without data loss.
SSTable
Flushing the in-memory memtable to a persistent, immutable on-disk structure—an SSTable—is typically triggered by one of three conditions.
First, individual buffer saturation. Once an active memtable reaches its predefined memory limit, it is marked immutable and flushed to disk in a single sequential pass, avoiding random I/O and in-place updates.
Second, global memory pressure. To prevent unbounded RAM usage, storage engines track the aggregate size of all memtables. If the total exceeds a global threshold, the engine may preemptively flush the largest memtable, even if it has not yet reached its individual limit.
Third, WAL growth control. To prevent the write-ahead log from growing indefinitely—leading to long recovery times—the engine may flush the oldest memtable. Once its contents are safely persisted as an SSTable, the corresponding WAL segments can be discarded4.
Making on-disk files immutable significantly simplifies concurrency control. Immutable SSTables can be read concurrently without locks on the data itself: readers never block writers, and readers never block each other. In contrast, mutable on-disk data structures such as B-trees rely on hierarchical locking to preserve consistency, allowing concurrent readers but requiring exclusive locks for writers—an approach that introduces complexity and contention.
An SSTable is an on-disk file containing key–value pairs sorted by key. It has several defining properties:
- It is immutable once written.
- It may contain multiple versions of the same key.
- Keys and values are treated as arbitrary byte strings, with no padding or schema requirements.
- Updates and deletes never modify existing data. Updates write a new version of the key into the memtable, which is later flushed to a new SSTable. Deletes are represented by tombstone records. During reads, the system always searches from newest to oldest, ensuring the most recent value or tombstone is observed first5.
The SSTable file format is optimized for sequential writes, efficient point lookups, range scans, and compaction. Physically, it consists of a data section followed by index, filter, metadata, and footer sections, each designed to minimize I/O and read amplification.
SSTable file
├── Data section (data blocks)
├── Index section
├── Filter section (Bloom filter)
├── Metadata / summary
└── Footer
The data section is divided into fixed-size data blocks, which are the smallest independently readable units of an SSTable. Each block stores a sorted sequence of key–value entries. Because keys and values are variable-length, entries include length metadata. Data blocks are typically prefix-compressed and checksummed, using compression algorithms such as Snappy, LZ4, Zstandard, Zlib, or Bzip2. Restart arrays enable binary search within compressed blocks by storing periodic full keys and their offsets.
Data block
├── Entry 1: (key₁, value₁)
├── Entry 2: (key₂, value₂)
├── …
├── Entry n
├── Entry metadata (lengths / offsets)
├── Restart points
└── Checksum
Each SSTable includes a sparse index, mapping keys—often the last key in each data block—to byte offsets. This allows the engine to locate the correct block with minimal I/O. An optional Bloom filter enables fast negative lookups, allowing the engine to skip both index and data blocks entirely when a key is known not to exist. Metadata records key ranges and statistics used by query planning and compaction, allowing entire files to be skipped. The footer is a fixed-size structure that makes the file self-describing, containing pointers to critical sections, a format version, and a magic number.
At a higher level, SSTables are often understood in terms of segments: contiguous groups of data blocks corresponding to a single memtable flush or a logical key range. Segments are immutable snapshots of database state at a particular point in time. While data blocks are the unit of I/O, segments help organize compaction and range scans.
Segment
├── Data block
├── Data block
├── Data block
├── Local metadata
└── Optional local index
If all SSTables were kept in a flat namespace, reads would need to consult many files, disk usage would grow due to duplicate and obsolete entries, and compaction would become increasingly expensive. Instead, SSTables are organized into levels that bound read cost, control space amplification, and make compaction predictable.
The core invariants of leveled organization are:
- Newer data resides in higher levels; older data moves downward via compaction.
- Each level is larger than the previous one by a fixed factor.
- Except for Level 0, SSTables within a level have non-overlapping key ranges.
Level 0 (L0) contains SSTables created directly from memtable flushes. These files are individually sorted but may have overlapping key ranges, allowing flushes to proceed without coordination and maximizing write throughput. To limit read amplification, the total size of L0 is bounded. Lower levels (L1 through Ln) contain compacted data with non-overlapping key ranges, ensuring that at most one SSTable per level must be consulted for any given key.
+-------------------------------------------------------------+
| On Disk |
+-------------------------------------------------------------+
+-------------------------------------------------------------+
| Level 0 (L0) – flush level |
+-------------------------------------------------------------+
| +-------------------+ +-------------------+ +-------------------+ |
| | SSTable L0-1 | | SSTable L0-2 | | SSTable L0-n | |
| | - overlapping | | - overlapping | | - overlapping | |
| | - recently flushed| | - recently flushed| | - recently flushed| |
| | - smallest size | | - smallest size | | - smallest size | |
| +-------------------+ +-------------------+ +-------------------+ |
+-------------------------------------------------------------+
+-------------------------------------------------------------+
| Level 1 (L1) – sorted, non-overlapping |
+-------------------------------------------------------------+
| +-------------------+ +-------------------+ +-------------------+ |
| | SSTable L1-1 | | SSTable L1-2 | | SSTable L1-n | |
| | - sorted key range| | - sorted key range| | - sorted key range| |
| | - no overlap | | - no overlap | | - no overlap | |
| | - larger than L0 | | - larger than L0 | | - larger than L0 | |
| +-------------------+ +-------------------+ +-------------------+ |
+-------------------------------------------------------------+
+-------------------------------------------------------------+
| Level 2 (L2) – larger, colder data |
+-------------------------------------------------------------+
| +-------------------+ +-------------------+ +-------------------+ |
| | SSTable L2-1 | | SSTable L2-2 | | SSTable L2-n | |
| | - wider key range | | - wider key range | | - wider key range | |
| | - lower updates | | - lower updates | | - lower updates | |
| | - higher read amp | | - higher read amp | | - higher read amp | |
| +-------------------+ +-------------------+ +-------------------+ |
+-------------------------------------------------------------+
+-------------------------------------------------------------+
| Level n (Ln) – coldest data |
+-------------------------------------------------------------+
| +-------------------+ +-------------------+ +-------------------+ |
| | SSTable Ln-1 | | SSTable Ln-2 | | SSTable Ln-n | |
| | - largest files | | - largest files | | - largest files | |
| | - rarely compacted| | - rarely compacted| | - rarely compacted| |
| | - highest density | | - highest density | | - highest density | |
| +-------------------+ +-------------------+ +-------------------+ |
+-------------------------------------------------------------+
Immutability inevitably leads to many SSTables accumulating on disk. Compaction addresses this by merging segments, retaining only the newest version of each key, discarding obsolete tombstones, and deleting old files once new compacted output has been safely written. In doing so, compaction restores space efficiency while preserving the invariants required for efficient reads.
Read, Write Paths
Compaction
Amplification quantifies how much extra work a storage engine performs relative to the logical operation requested by the client. In practice, this work appears in three forms: read amplification, write amplification, and space amplification.
Read amplification is the ratio of bytes read from storage to retrieve a value relative to the logical size of that value. It often manifests as the number of files, blocks, or disk I/O operations required to satisfy a single logical read.
Write amplification is the ratio of bytes written to storage to persist a value relative to the logical size of that value. Write amplification arises when a single logical write triggers multiple physical writes, typically due to reorganization or compaction.
Space amplification is the ratio of the total amount of data stored on disk to the size of the logical dataset. It captures how much extra space the system consumes beyond the user’s actual data.
The RUM conjecture states that any storage engine can optimize at most two of the following three dimensions:
- read amplification
- write (update) amplification
- space (memory) amplification
Optimizing any two necessarily worsens the third.
Amplification in B-Tree vs. LSM-Based Storage Engines
In B-tree storage engines, a single logical write may:
- update a leaf page,
- trigger a page split if the page is full, and
- require updates to parent nodes to accomodate new separator keys.
These operations can cascade up the tree, potentially reaching the root. As a result, a single logical write can cause multiple page writes. Because pages are scattered across disk, these writes are largely random I/O. Write amplification in B-trees primarily comes from this structural maintenance. It is usually moderate but unpredictable, depending on page occupancy and split frequency.
In LSM engines, the same key–value pair may be rewritten many times before reaching its final level on disk. Consequently, write amplification is dominated by compaction. While it is tunable, it is often lower than in B-trees.
Reads in B-trees follow a single, well-defined path: one page per level from root to leaf. Due to the high fanout of B-trees, the tree height is small. This results in low, predictable read amplification and efficient point lookups and range scans. Read amplification is bounded by the tree height, largely independent of dataset size, and can be further reduced by caching upper-level pages.
In contrast, reads in LSM engines must account for multiple possible data locations:
- mutable and immutable memtables, and
- multiple SSTables across levels.
Even with optimizations such as Bloom filters and sparse indexes, read amplification remains higher than in B-trees. LSM engines deliberately trade higher read amplification for substantially higher write throughput.
Space amplification in B-trees mainly arises from partially filled fixed-size pages and internal fragmentation. In LSM engines, space amplification is caused by multiple versions of the same key existing across SSTables, along with tombstones and obsolete entries that are retained until compaction. In practice, space amplification in LSM engines depends on:
- the compaction strategy,
- the level size ratio, and
- workload characteristics.
Without compaction, several pathological behaviors emerge in LSM-backed storage engines:
- unbounded disk growth,
- increased read amplification, and
- excessive space amplification.
Compaction addresses these issues by:
- reclaiming disk space through the removal of obsolete versions and tombstones,
- reducing the total number of SSTables, and
- enforcing structural invariants such as non-overlapping key ranges.
At its core, compaction is a merge-sort operation over SSTables. The system selects a subset of SSTables as input and merges them into one or more new SSTables. Records are processed in key order, typically using a merge heap (for example, a priority queue). When multiple records with the same key are encountered, the engine retains the record with the highest sequence number or timestamp, representing the most recent write. Older versions are discarded, and tombstones suppress older values and may themselves be dropped once it is safe to do so.
The output of compaction is a smaller number of new SSTables containing only the latest versions of keys, organized such that key ranges are non-overlapping. Once the new SSTables are fully written, the original input SSTables are deleted and their disk space reclaimed. Compaction is performed by a dedicated compaction thread pool that runs asynchronously in the background while foreground reads and writes continue concurrently. It is typically triggered by heuristics such as:
- SSTable counts per level, and
- SSTable size thresholds.
LSM compaction closely resembles generational garbage collection, guided by the weak generational hypothesis that most objects die young. Recently flushed SSTables contain many short-lived versions of keys and therefore experience high churn and frequent compaction. Older SSTables mostly contain stable, long-lived data and are compacted infrequently. This analogy helps explain why LSM trees can sustain high write throughput: most write amplification is concentrated on young data, while older data remains largely untouched.
Tiered Compaction
Tiered or size-based, compaction groups SSTables by size rather than by key range. When a fixed number of similarly sized SSTables accumulate within a tier, they are merged into a single larger SSTable. This process repeats hierarchically as larger files accumulate over time.
Each tier has both a size limit and a maximum number of SSTables. When a tier reaches capacity, all SSTables in that tier are merged and written to the next tier. SSTables within the same tier may have overlapping key ranges. The key distinction between tiered and leveled compaction is that tiered compaction merges SSTables only within a tier (Li -> Li+1), whereas leveled compaction merges SSTables across adjacent levels (Li + Li+1 -> Li+1).
Tiered compaction offers lower write amplification than leveled compaction because data is rewritten fewer times. It is particularly well-suited for write-heavy workloads, as it amortizes compaction cost into infrequent, sequential bulk merges rather than continuous cross-level reorganization. The trade-offs are higher read amplification and higher space amplification. Because SSTables within a tier may overlap arbitrarily and compaction occurs only when an entire tier fills, obsolete versions of keys can persist for a long time.
Writes
│
▼
┌──────────────────────────────────────────────────────────────┐
│ Tier 0 │
│ Small SSTables of similar size │
│ Overlapping key ranges allowed │
│ │
│ ┌──────────┐ │
│ │ SSTable 1│ [ 0 – 300 ] │
│ └──────────┘ │
│ ┌──────────┐ │
│ │ SSTable 2│ [ 200 – 500 ] │
│ └──────────┘ │
│ ┌──────────┐ │
│ │ SSTable 3│ [ 100 – 400 ] │
│ └──────────┘ │
│ ┌──────────┐ │
│ │ SSTable 4│ [ 250 – 600 ] │
│ └──────────┘ │
│ ┌──────────┐ │
│ │ SSTable 5│ [ 50 – 350 ] │
│ └──────────┘ │
│ │
└───────────────┬──────────────────────────────────────────────┘
│ Compaction triggered when tier is full
▼
┌──────────────────────────────────────────────────────────────┐
│ Tier 1 │
│ Larger SSTables (Merged Output) │
│ Overlap Still Allowed Within Tier │
│ │
│ ┌──────────────────────────────┐ │
│ │ SSTable A │ │
│ │ ~5× Larger Than Tier 0 Files │ │
│ │ [ 0 – 600 ] │ │
│ └──────────────────────────────┘ │
└───────────────┬──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────────┐
│ Tier 2 │
│ Even Larger SSTables │
│ Fewer Files, but Overlap Still Allowed │
└──────────────────────────────────────────────────────────────┘
Leveled Compaction
Leveled compaction organizes data into a sequence of levels (L0, L1, L2, …), each with strict size and key-range invariants. As data moves down the levels, it becomes progressively denser, covering a larger fraction of the key space. Each level typically grows exponentially relative to the previous level (the fanout) and has a maximum total size. L0 files may overlap arbitrarily but levels L1 and above are guaranteed to have non-overlapping key ranges, ensuring that within these levels, at most one SSTable needs to be checked for any given key. When a level Li exceeds its size or SSTable count threshold, one or more SSTables from Li, any overlapping SSTable from Li+1 are selected and merged. If the merge output exceeds the maximum SSTable size of Li+1, then it is split into multiple fixed-size SSTables which are non-overlapping and the original input SSTables are deleted.
Leveled compaction provides much lower read amplification than tiered compaction. Read amplification is bounded by the number of L0 SSTables + (the number of levels - 1) . Space amplification is also lower, as obsolete entries and tombstones are cleaned up aggressively. This strategy is therefore well-suited for read-heavy workloads, delivering predictable, low-latency reads at the cost of higher write amplification.
Writes
│
▼
┌───────────────────────────────────────────────────────────────────┐
│ L0 │
│ Flush Level │
│ • Many small SSTables │
│ • Arbitrary overlap allowed │
│ │
│ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │ S0a │ │ S0b │ │ S0c │ │ S0d │ │
│ │[50–90] │ │[ 0–40] │ │[30–70] │ │[10–80] │ │
│ └────────┘ └────────┘ └────────┘ └────────┘ │
│ │
│ (Multiple SSTables may need to be consulted for a single key) │
└───────────────────────┬───────────────────────────────────────────┘
│ Flush / Compaction
▼
┌───────────────────────────────────────────────────────────────────┐
│ L1 │
│ • Fixed maximum total size (e.g., 100 MB) │
│ • Non-overlapping key ranges │
│ • At most ONE SSTable checked per key │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ SSTable A │ │ SSTable B │ │ SSTable C │ │
│ │ [ 0 – 100 ] │ │ [101 – 200 ] │ │ [201 – 300 ] │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ ▲overlapping key range │
│ │ │
│ Selected SSTable(s) for compaction │
└───────────────────────┬───────────────────────────────────────────┘
│ L1 exceeds size / file-count threshold
▼
┌─────────────────────────────────────────────────────────────────────┐
│ Compaction: L1 → L2 │
│ │
│ Inputs: │
│ • SSTable B [101–200] (from L1) │
│ • SSTable D [120–260] (overlapping SSTable from L2) │
│ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Merge Key Streams │ │
│ │ (resolve deletes, overwrite older) │ │
│ └──────────────────────────────────────────────┘ │
│ │
│ Output exceeds max SSTable size → SPLIT │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ SSTable D′ │ │ SSTable E′ │ │ SSTable F′ │ │
│ │ [101–150] │ │ [151–220] │ │ [221–260] │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ (All output SSTables are fixed-size and non-overlapping) │
│ │
│ Original input SSTables are DELETED │
└───────────────────────┬─────────────────────────────────────────────┘
▼
┌───────────────────────────────────────────────────────────────────┐
│ L2 │
│ • Larger total size (fanout ≈ 8× L1) │
│ • Denser data, wider key coverage │
│ • Strict non-overlapping invariant │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ SSTable D′ │ │ SSTable E′ │ │ SSTable F′ │ │
│ │ [101–150] │ │ [151–220] │ │ [221–260] │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ (As levels increase, data becomes denser and more complete) │
└───────────────────────────────────────────────────────────────────┘
RocksDB uses a hybrid compaction strategy: L0 employs tiered compaction to enable fast memtable flushes, while levels L1 and above use leveled compaction to bound read amplification.
| Dimension | Leveled Compaction | Tiered Compaction |
|----------------------|--------------------|---------------------|
| Write Amplification | High | Low |
| Read Amplification | Low | High |
| Space Amplification | Low | High |
| Key-Range Overlap | None (≥ L1) | Allowed Everywhere |
| Compaction Input | Lᵢ + Lᵢ₊₁ | Lᵢ Only |
| Compaction Output | Written to Lᵢ₊₁ | Written to Lᵢ₊₁ |
| Workload Fit | Read-Heavy | Write-Heavy |
Optimisations
Modern LSM implementations employ a layered set of optimizations to reduce read amplification. These techniques progressively narrow the search space, minimize disk I/O, and bound CPU overhead.
Compaction remains the primary mechanism for controlling read amplification. By merging SSTables and removing obsolete versions of keys, the system reduces the number of data locations that must be consulted during a read.
Each SSTable maintains a sparse index loaded into memory. This index maps key ranges to disk offsets, allowing the engine to quickly locate the approximate position of a key without scanning the entire file.
Bloom filters prevent unnecessary reads by identifying SSTables that definitely do not contain a target key. Most LSM engines maintain one Bloom filter per SSTable. Bloom filters are especially effective in early levels, where SSTables contain relatively few keys. A very low false-positive rate can be achieved with minimal memory, and because early levels are consulted first, eliminating I/O at these levels yields disproportionate latency gains, as shown by Dayan et al., 2017.
Allocating more bits to early-level Bloom filters, rather than distributing them uniformly across all levels, minimizes overall read cost. While Bloom filters reduce disk I/O, they introduce CPU overhead. Each Bloom filter check requires hashing the lookup key, and as the number of SSTables grows, repeated hashing can become expensive. A key insight to reduce this overhead is sharing the computed hash digest across Bloom filters at different levels. This approach requires coordinated Bloom filter implementations but significantly reduces CPU work, as described in Zhu et al., 2023.
Frequently accessed data is cached at the block level, reducing repeated disk reads for hot keys.
LSM engines such as LevelDB and RocksDB maintain a manifest file that records all SSTables across levels, their key ranges, and lifecycle metadata. The manifest is loaded into memory and cached, enabling the engine to quickly determine which SSTables may contain a given key. Because the manifest is updated only when metadata changes, it imposes no overhead on the normal read or write path.
Outro
“How a Two-Component LSM-tree Grows
To trace the metamorphosis of an LSM-tree from its very first insertion, we begin with the memory-resident C0 component.”
O’Neil et al. (1996) posed the question: “What if we stopped paying the cost of random I/O for every update and instead, amortized it over time?” They proposed two designs: a two-component LSM-tree, with a memory-resident C0 optimized for CPU efficiency and a disk-resident C1 optimized for sequential I/O; and a multi-component generalization, where data flows through increasingly larger disk components. Updates first accumulate in memory and then migrate to disk via the rolling merge cursor, a conceptual mechanism that manages the continuous, asynchronous movement of data between components. Rather than performing a single massive update, the system moves data in small, manageable steps to keep memory usage in check. The efficiency of this process is captured by the batch-merge parameter M, representing the average number of entries merged from C0 into each page of C1. A higher M reduces disk arm movement and lowers per-insert I/O costs. In multi-component trees (C0, C1, C2, …, Ck), asynchronous rolling merge processes occur between every adjacent pair of components. Using more than two components allows the memory-resident C0 to remain smaller while maintaining high I/O efficiency, especially when C1 becomes very large.
Key Differences Between O’Neil’s Design and Modern Engines
Rolling Merge vs. Discrete Compaction
O’Neil et al. proposed a conceptual cursor that moves data from C0 to C1 by reading “emptying blocks” and writing “filling blocks” in a constant, circulating stream. Modern engines like RocksDB and Pebble do not use a rolling cursor. Instead, they employ compaction—a discrete event triggered when a level or SSTable reaches a size threshold. Entire SSTables are merged at once, rather than using a continuous rolling process.
B-Tree-Like Directory vs. Immutable SSTables
The original C1 component was described as having a “directory structure comparable to a B-Tree” optimized for sequential disk access. Modern engines, in contrast, use immutable, sorted string tables (SSTables). Thousands of small SSTables are organized into levels, rather than a single large, growing tree.
Concurrency and Locking
O’Neil et al. proposed node-level locking: when the rolling merge cursor modifies a node, it is locked in write mode, and reads are blocked or redirected. Modern engines leverage MVCC (Multi-Version Concurrency Control). Background compactions create new versions of SSTables, and pointers are atomically switched once the new file is ready. This allows reads to continue uninterrupted, eliminating the need for node locks.
Google’s work in the early 2000s demonstrated that LSM-trees could scale efficiently across distributed environments. While O’Neil et al. provided the theory and asymptotic guarantees for write efficiency, Google gave practical, fault-tolerant implementations capable of surviving machine failures and operational complexity.
- SSTable format (circa 2003): established immutable, ordered files as the fundamental on-disk unit.
- Bigtable (Chang et al., 2006): layered SSTables behind a tablet abstraction, combining in-memory buffering, on-disk SSTables, and background compactions to scale across thousands of machines.
Other Log-Structured Storage Systems
Bitcask, WiscKey, Jungle illustrate how log-structured designs can be specialized, either by relaxing ordering, separating data, or changing on-disk indexes. They all retain the core principle of sequential writes and deferred reorganization, exploring different points in the read/write/space trade-off space.
Bitcask: Unordered Log-Structured Storage
Bitcask is a purely append-only, unordered key–value store originally developed for Riak. It can be viewed as an extreme LSM-like design with no memtables, no SSTables, and no sorted structure on disk. All updates are sequentially appended to log files. When a log file reaches a size threshold, it is sealed and a new log is created. An in-memory hash map tracks the latest version of each key, pointing to its log file and offset. Reads require only a single random seek, and writes are sequential. Space is reclaimed through periodic log compaction, rewriting only live key–value pairs. Bitcask excels in workloads that demand high write throughput and efficient point reads.
WiscKey: Key–Value Separation
WiscKey reduces write amplification by separating keys from values. Keys and value pointers are stored in a sorted LSM-tree, while values are appended to an unsorted value log (VLog). During compaction, only small key-pointer entries are rewritten; large values remain in the VLog and are compacted independently. This approach drastically reduces write amplification for large values while preserving efficient point lookups and range queries.
Jungle: LSM-tree with Copy-on-Write B+-Tree
Jungle targets the tiered LSM-tree trade-off: low write amplification but high read amplification due to multiple overlapping SSTables per level. Instead of maintaining each level as a set of SSTables, Jungle uses an append-only copy-on-write B+-Tree per level. This preserves low write amplification while allowing efficient key lookups within a level. As a result, Jungle achieves write amplification comparable to tiered LSM-trees and read amplification closer to leveled LSM-trees.
References
- The Log-Structured Merge-Tree (O’Neil et al.)
- CMU 15-445 — Storage II: LSM Trees
- A Brief History of Log-Structured Merge Trees
- MemTable, WAL, SSTable — LSM Trees Explained
- Log-Structured Merge Trees (Ben Stopford)
- LSM Trees (Yet Another Dev Blog)
- LSM Trees: Memtables & SSTables
- Bloom Filter Hash Sharing
- Leveling in LSM Trees
- How RocksDB Works
- Fine, I’ll Play with Skiplists
- A Deep Dive into LSM Tree Architecture
- Log-Structured Storage
- Understanding LSM Trees in 5 Minutes
Not all B-tree designs suffer equally from write amplification. Copy-on-Write (CoW) B-trees avoid in-place updates by writing new versions of modified nodes and updating parent pointers. This reduces random overwrites and can turn some writes into sequential I/O, but each update still touches O(logb n) nodes, so write overhead remains proportional to tree height. Write-optimized or partitioned B-trees buffer recent inserts into separate partitions, merging them periodically into the main tree. This groups writes and reduces random I/O, improving throughput over traditional B-trees. Yet, because the structure remains ordered, merges still involve multiple page writes, and write amplification grows with tree size. In both cases, these variants mitigate but do not eliminate the fundamental write limitations of B-trees. LSM trees, by contrast, achieve higher sustained write throughput by fully decoupling updates from random I/O through in-memory buffering and sequential, batched disk flushes. ↩︎
The exact boundary between the differential and the base index depends on factors such as the fanout and the compaction strategy used in the LSM tree implementation. Fanout (size ratios) controls how much data accumulates at a given level before compaction is triggered. When the size ratio is relatively small, compaction occurs frequently, moving data downward quickly—keeping the differential index small while the base index begins higher in the tree. In contrast, a larger size ratio results in infrequent compactions, causing data to linger longer in the upper levels, creating a larger differential region while the base index begins deeper in the tree. The compaction strategy determines how aggressively newer data is merged downward, directly controlling how long data remains “differential.” ↩︎
Skip lists are often overlooked in favor of B-trees due to poor cache locality. The main issue is pointer chasing. A skip list is essentially a multi-level linked list, and in a standard implementation, each new node is allocated on the general system heap (using malloc). This results in spatial fragmentation, as nodes are scattered across RAM. When the CPU follows a pointer to the next node, that memory address is rarely in the L1 or L2 cache, causing the CPU to stall while fetching data from DRAM. These cache misses accumulate into a significant performance penalty, especially given that a skip list has multiple levels. ↩︎
As seen in scenarios 2 and 3, a memtable can be flushed before it is full. This is one reason the generated SST file can be smaller than the corresponding memtable. Another reason is the use of block-based compression, which further reduces the size of SST files relative to the flushed memtable. ↩︎
Counterintuitively, delete operations initially consume disk space. The actual data is physically removed only during compaction, when obsolete updates and tombstones are merged away. ↩︎